CapyMOA#





CapyMOA does efficient machine learning for data streams in Python. A data stream is a sequences of items ariving one-by-one that is too large to efficiently process non-sequentially. CapyMOA is a toolbox of methods and evaluators for: classification, regression, clustering, anomaly detection, semi-supervised learning, online continual learning, and drift detection for data streams.
Install with pip:
pip install capymoa
Refer to the Setup guide for other options, including CPU-only and dev dependencies.
from capymoa.datasets import Electricity
from capymoa.classifier import HoeffdingTree
from capymoa.evaluation import prequential_evaluation
# 1. Load a streaming dataset
stream = Electricity()
# 2. Create a machine learning model
model = HoeffdingTree(stream.get_schema())
# 3. Run with test-then-train evaluation
results = prequential_evaluation(stream, model)
# 3. Success!
print(f"Accuracy: {results.accuracy():.2f}%")
Next, we recomend the Tutorials.
If you use CapyMOA in your research, please cite us using the following Bibtex entry:
@misc{
gomes2025capymoaefficientmachinelearning,
title={{CapyMOA}: Efficient Machine Learning for Data Streams in Python},
author={Heitor Murilo Gomes and Anton Lee and Nuwan Gunasekara and Yibin Sun and Guilherme Weigert Cassales and Justin Jia Liu and Marco Heyden and Vitor Cerqueira and Maroua Bahri and Yun Sing Koh and Bernhard Pfahringer and Albert Bifet},
year={2025},
eprint={2502.07432},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2502.07432}
}
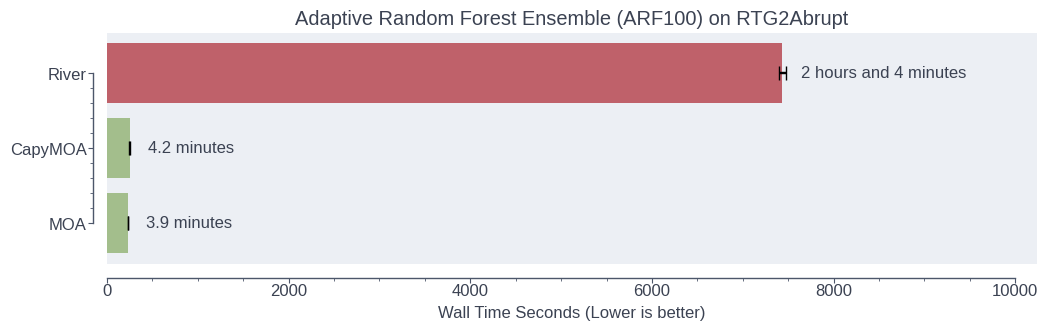
Benchmark comparing CapyMOA against other data stream libraries [1].#
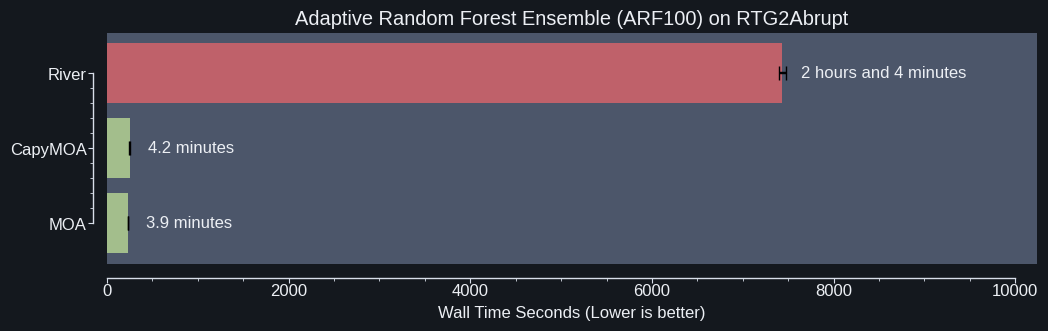
Benchmark comparing CapyMOA against other data stream libraries [1].#
Warning
CapyMOA is still in the early stages of development. The API is subject to change until version 1.0.0. If you encounter any issues, please report them on the GitHub Issues page or talk to us on Discord.